Status: Live in Playground · Try it: synap.maximem.ai/playground
Open the playground and pick Uber: Customer Support to see the reference implementation running before you build.
What you’ll build
A chat agent that:- Recalls rider context: communication preferences, prior issues, frequent destinations
- Grounds in real data: pulls recent rides via tools before suggesting actions
- Resolves common issues: refunds, lost items, rating disputes, charge disputes
- Escalates cleanly: opens a Tier-2 ticket with a memory-aware summary
When to use this recipe
Build this if your product:- Has authenticated end users with a stable internal user ID
- Has internal APIs the agent can call (orders, accounts, tickets, refunds)
- Wants the agent to remember resolutions so the user doesn’t re-explain on the next chat
- Needs a deterministic escalation path to a human queue
Architecture at a glance
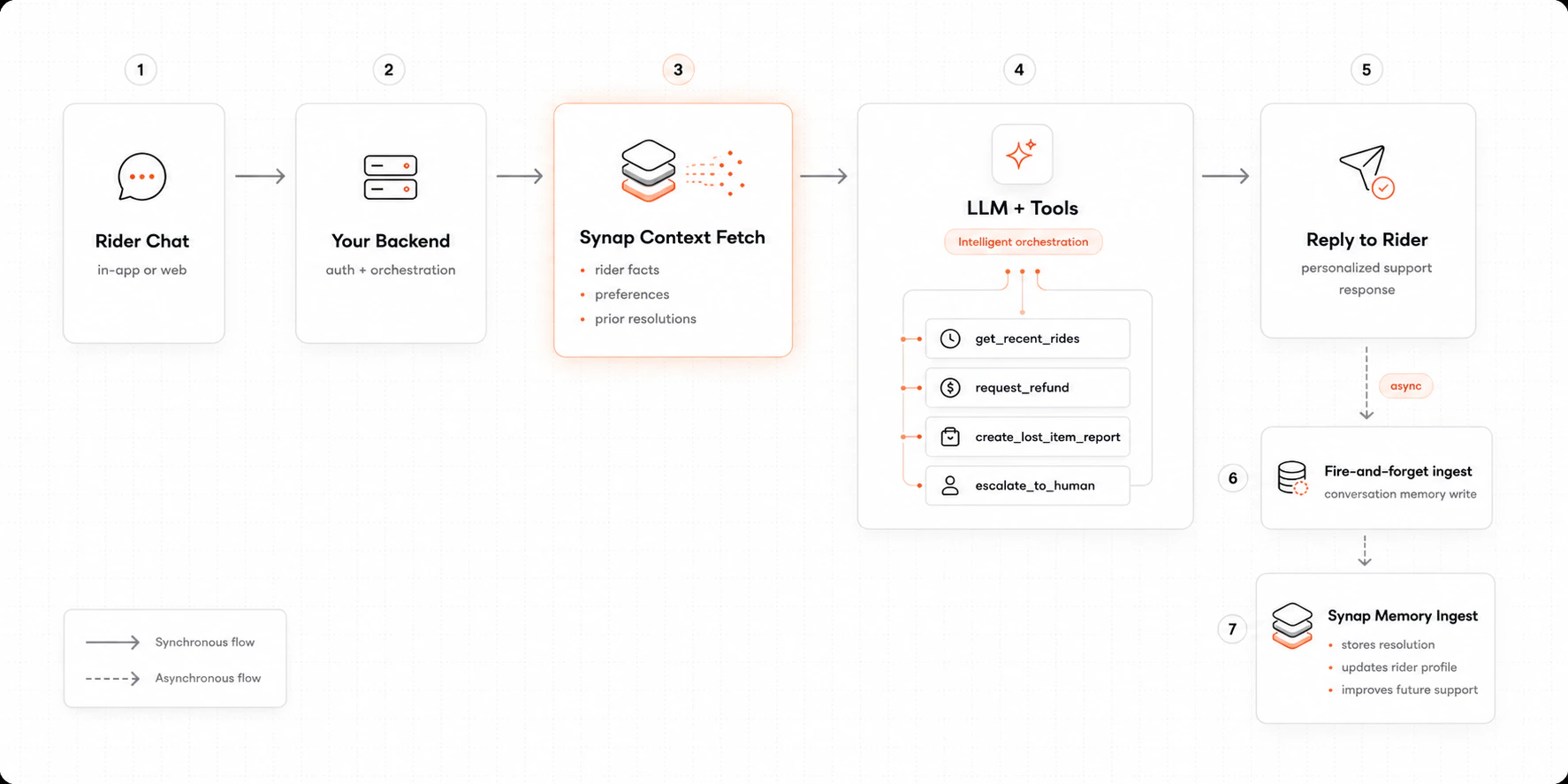
Stack
| Layer | Choice |
|---|---|
| Synap SDK | maximem-synap (Python) / @maximem/synap-js-sdk (TypeScript) |
| Framework | OpenAI Agents SDK (Python) / Vercel AI SDK (TypeScript) |
| Memory adapter | maximem-synap-openai-agents / @maximem/synap-vercel-adk |
| LLM | OpenAI gpt-4o (swap for any supported model) |
| Channel | Your existing chat surface (in-app, web widget, etc.) |
Prerequisites
- A Synap API key, see Authentication
- Internal APIs for ride history, refunds, lost items, and tickets (real or stubbed for development)
- Python recipe: Python 3.11+
- TypeScript recipe: Node 18+ and Python 3.11+ on the host (the JS SDK wraps the Python SDK as a subprocess)
Install
Configure
Build it
1. Identity & scoping
Three scopes do the work:customer_id = "uber": single tenant; this is Uber’s own productuser_id = <stable rider ID>: comes from your authenticated session, never trust the clientconversation_id = <session UUID>: one per chat session, stable across messages in the same session
conversation_id, user_id, and customer_id must be valid UUIDs. Generate session ids with crypto.randomUUID() (JS) or str(uuid.uuid4()) (Python), as shown below.2. Business tools
The agent calls these to ground replies in real account state and to take action. Wire each one to your internal API.3. System prompt
Tight, outcome-focused, and explicit about memory and escalation rules.System prompt
4. Wire memory + LLM + tools
The Python path uses the OpenAI Agents integration to exposesynap_search and synap_store as tools the agent can call when it wants to recall or remember. The TypeScript path uses the Vercel AI SDK integration which wraps the model: context fetch and turn ingestion happen automatically on every call, so you only declare your business tools.
- Python’s
synap_search/synap_storeare tools the LLM decides to call. The model has agency over when to recall and when to store. - TS’s
synap.wrapis middleware. Memory is fetched on every call and the turn is ingested afterward, unconditionally. Less control, less code.
Run & verify
Stand up the handler behind any HTTP framework (FastAPI, Next.js route handler, etc.) and send two messages from different sessions to see memory carry across:Session 1
Session 2 (next day, new conversation_id)
conversation_id; Synap pulls “prefers texts not calls” and “lost-item report open” from the rider’s long-term memory.
Inspect what got stored
Customize / extend
- Voice channel → swap the chat handler for Voice Concierge (Pipecat + ElevenLabs). Same scoping model, different I/O.
- Multi-tenant flavor (B2B Uber-for-X) → set
customer_idper tenant org. See Patterns → Multi-Tenant SaaS. - Different framework → drop the OpenAI Agents / Vercel AI SDK adapter; the SDK calls (
memories.create,conversation.context.fetch) work standalone. See AI Integrations. - Slack human-handoff side-channel → when
escalate_to_humanfires, post into Slack using the Slack pattern. The Tier-2 agent has the full memory thread. - Catalog-grounded variant → see Amazon: Shopping Assistant for the same shape with product retrieval added.
Troubleshooting
Rider isn’t getting personalized replies- Check
user_idis stable across sessions; derive it from authenticated session, not from the chat client. - Confirm ingestion is firing. The fire-and-forget pattern (
asyncio.create_task) swallows errors silently; log inside the task during development.
user_idcollision somewhere upstream. Audit the auth flow.- For B2B variants, also confirm
customer_idis set per tenant.
- A tool returned an empty result and the model hallucinated. Tighten tool docstrings, return explicit “no rides found” structures, and lower temperature.
- You’re probably on Edge Runtime. Add
export const runtime = "nodejs"to your route handler. The JS SDK requires Node + Python on the host.
Related
- Integrations: OpenAI Agents SDK · Vercel AI SDK
- Concepts: Customized Memory Architectures · Memory Scopes · Conversational Context Lifecycle
- Patterns: Multi-Tenant SaaS · Graceful Degradation
- Vity: Maximem Vity overview