Entity resolution runs automatically during ingestion. No additional SDK calls are needed. Every document that passes through the ingestion pipeline has its entities extracted and resolved before storage.
Why master data management matters
Traditional AI applications treat each conversation as isolated text. Over hundreds or thousands of interactions, the same entities appear under different names, in different contexts, and from different users. Without entity resolution, your agent has no way to connect “the CEO” mentioned in one conversation with “Maria Garcia” mentioned in another. The entity registry solves this by:- Consolidating identity: All references to the same real-world entity converge on a single canonical record, regardless of how they were originally mentioned
- Building organizational knowledge over time: Each conversation enriches the registry with new aliases, context, and relationships, making future resolution more accurate
- Enabling entity-centric retrieval: Instead of searching by keywords, you can retrieve all memories associated with a specific entity across all conversations and users
- Providing auditability: The registry tracks when each entity was first seen, last referenced, and how it has been resolved, giving you a clear provenance trail
How it works
Entity resolution is a multi-step process that runs as part of the ingestion pipeline: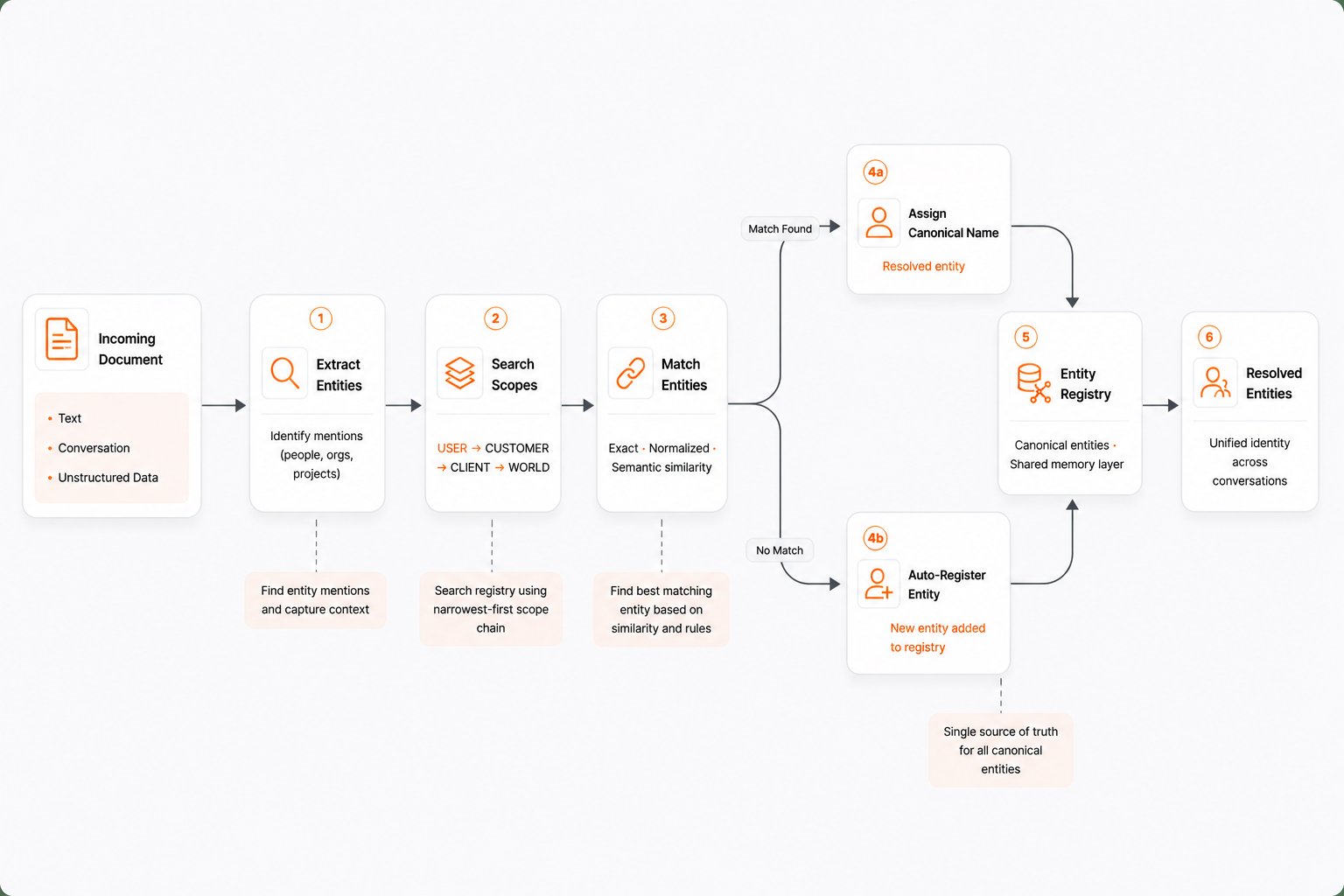
1
Extract entities from text
The ingestion pipeline identifies entity mentions in the incoming content. Entities include people, organizations, products, locations, and other named references. Each entity mention is extracted with its surrounding context.
2
Search the entity registry
Each extracted entity is matched against the entity registry. The search follows the scope chain (USER, CUSTOMER, CLIENT, WORLD), checking narrowest scopes first. Matching uses both exact text comparison and semantic similarity via vector embeddings.
3
Resolve or register
If a match is found, the entity mention is linked to the existing canonical entity. If no match is found, the entity is auto-registered at CUSTOMER scope for future lookups. Ambiguous matches (multiple possible candidates) can be queued for human review.
4
Apply canonical names
Resolved entities receive a
canonical_name that is consistent across all references. This canonical name is stored alongside the extracted memory, enabling precise retrieval by entity.The entity registry
The entity registry is a database of known entities, organized by scope (User → Customer → Client → World). It functions as the master data store for all entities your application encounters. Each registry entry contains:Scope-aware lookups
The registry is searched following the scope chain, narrowest first: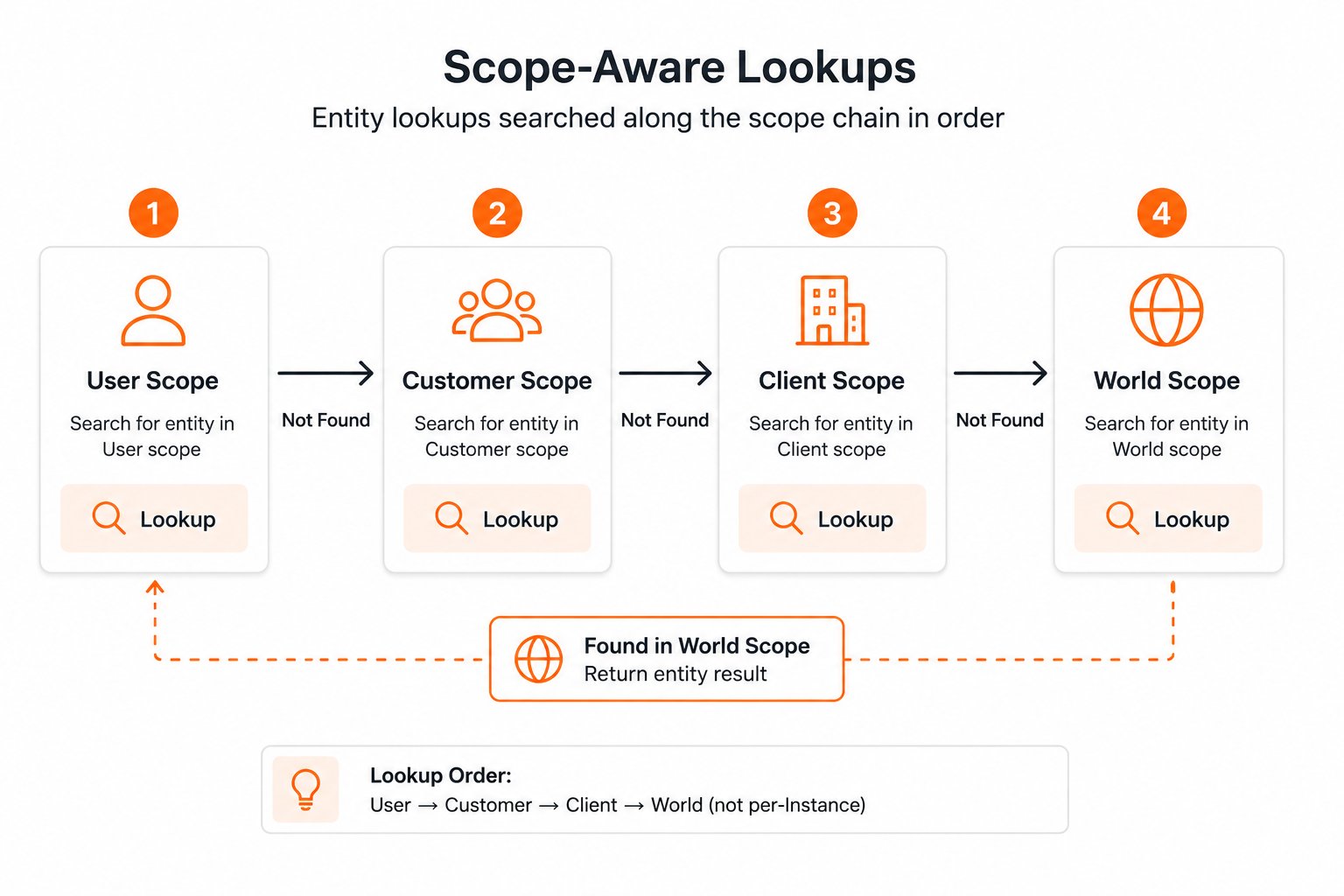
Matching strategies
Synap uses multiple matching strategies to resolve entities, applied in order of confidence:- Exact match
- Alias match
- Semantic match
- Contextual match
The extracted entity name exactly matches a canonical name or alias in the registry.
Auto-registration
When the resolution pipeline encounters an entity that does not match any existing registry entry, it automatically registers the entity at CUSTOMER scope. This means: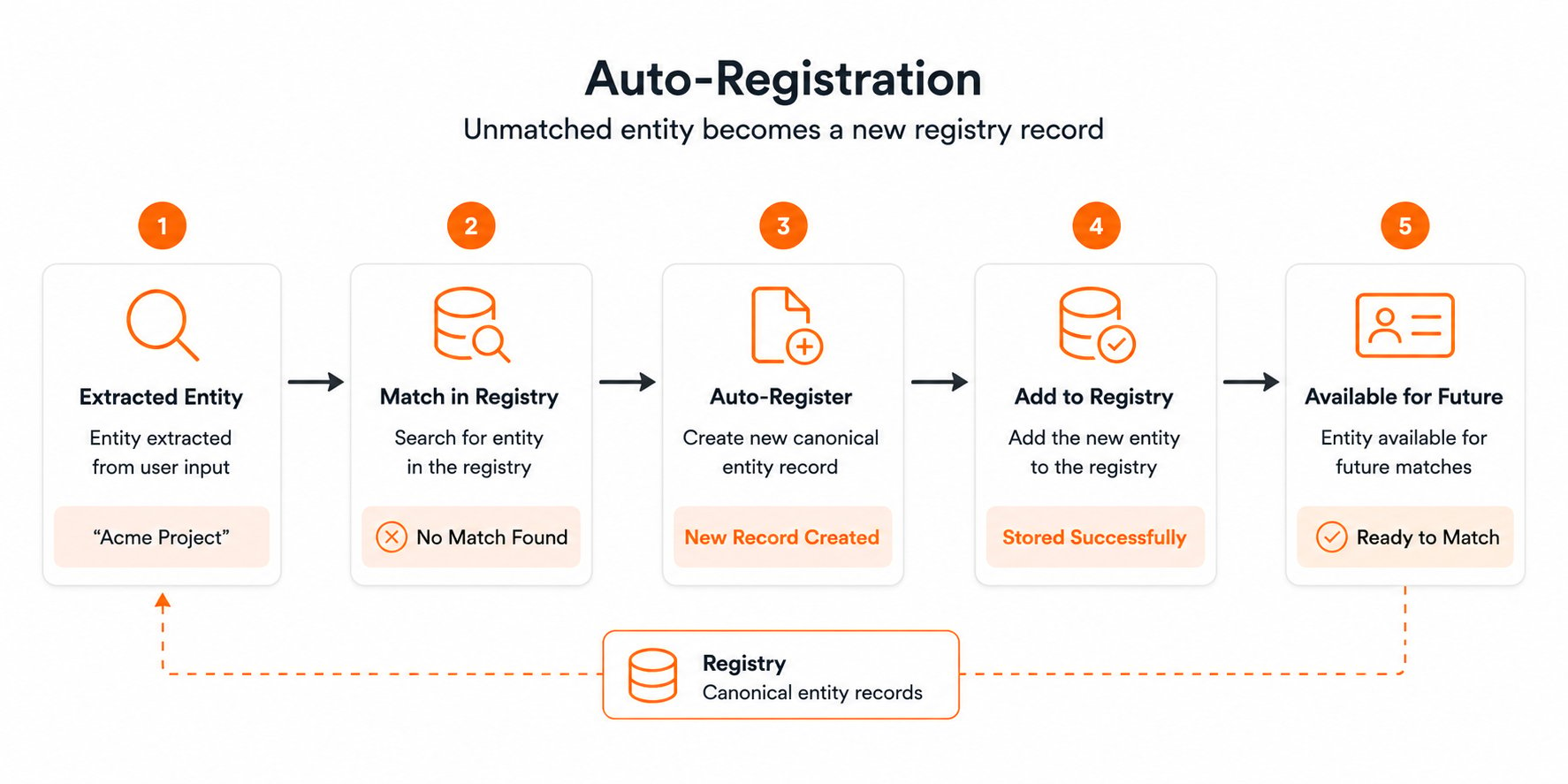
- The system learns new entities organically as conversations happen
- Future mentions of the same entity will resolve to the auto-registered entry
- No manual entity management is required for common use cases
- Auto-registered entities can be promoted, edited, or merged through the review queue
Auto-registration happens at CUSTOMER scope by default because it provides the right balance: entities are shared within an organization (so all users in that org benefit) but isolated from other organizations (preventing cross-tenant entity leakage).
The review queue
When the resolution pipeline encounters an ambiguous match (where multiple registry entries are plausible candidates) the entity is placed in a review queue for human review rather than making an incorrect automatic resolution.What triggers a review queue entry
- Multiple registry entries match with similar confidence scores
- A semantic match falls in the ambiguity zone (confidence between 0.5 and 0.8)
- An auto-registered entity closely resembles an existing entry (possible duplicate)
Managing the review queue
Review queue items appear in the Dashboard → Entities → Review queue view. From there you can merge ambiguous mentions into an existing canonical entity, create a new entity, or dismiss the match.SDK-level access to the review queue is on the roadmap. For now, resolution is dashboard-only. Contact [email protected] if you need programmatic access for a specific workflow.
Code examples
Automatic resolution during ingestion
Entity resolution happens transparently during ingestion. You do not need to make any special calls:Querying for entity-related context
To retrieve memories about a specific entity, pass the entity name (or canonical form) as a search query. Synap’saccurate retrieval mode does the heavy lifting: it traverses the entity graph to find memories linked to that entity, even when the entity isn’t named verbatim in the source text.
Entity types
Synap recognizes and categorizes entities into standard types:Best practices
Provide context in your documents
Provide context in your documents
The more context you include in ingested documents, the better entity resolution works. Full names, roles, and departments help distinguish between entities with similar names.Instead of: “Alex said the deadline is Friday.”
Prefer: “Alex Rivera from the billing team said the deadline is Friday.”
Use consistent customer_id values
Use consistent customer_id values
Entity resolution relies on scope boundaries. Ensure you use consistent
customer_id values across all ingestion calls for the same organization. Inconsistent IDs will fragment the entity registry.Review ambiguous matches promptly
Review ambiguous matches promptly
The review queue catches edge cases that automatic resolution cannot handle. Review these regularly to maintain entity registry quality. Unresolved queue items do not block ingestion: they use the best available match and flag it for review.
Let the system learn
Let the system learn
Auto-registration is designed to build the entity registry organically. Avoid manually populating the registry for every possible entity. Instead, let natural conversations populate it and use the review queue to catch errors.
Treat the registry as master data
Treat the registry as master data
The entity registry is not just a deduplication tool: it is your application’s master data store for entities. Invest in keeping it clean: merge duplicates, correct canonical names, and enrich metadata. The quality of entity resolution improves directly with registry quality.
Working with entity resolution in the SDK
Entity resolution is fully automatic. There are no explicit SDK calls to trigger or configure it. As you ingest more data throughsdk.memories.create(), Synap continuously builds and refines its entity registry, improving resolution accuracy over time. The sections below show how resolution surfaces in practice and how it interacts with retrieval.
Resolution across conversations
The following example demonstrates how entity resolution enriches retrieval results across multiple conversations and users. The same person is mentioned as “Sarah Chen”, “S. Chen”, and “Sarah” across three separate ingestions, and resolution links them all to one canonical entity.- Registered “Sarah Chen” during the first ingestion
- Resolved “S. Chen” to “Sarah Chen” during the second ingestion
- Resolved “Sarah” to “Sarah Chen” during the third ingestion (CUSTOMER scope match)
- Linked all extracted facts to the same canonical entity, enabling comprehensive retrieval
Impact on retrieval modes
Both retrieval modes benefit from entity resolution directly: resolved canonical entities give them the same graph linkage across conversations.accurate mode additionally adds LLM subquery decomposition and reranking on top.
For queries that span multiple conversations or involve entity relationships, both modes benefit from a well-populated entity registry;
accurate additionally trades extra latency for LLM-driven query decomposition and result reranking.
Next steps
Memories & Context
See how entity resolution fits into the full ingestion pipeline.
Memory Scopes
Understand the scope chain that entity lookups follow.
How Ingestion Works
How resolved entities are stored in the vector and graph engines during ingestion.