What is a Memory?
A Memory is a unit of structured knowledge that Synap extracts from raw documents. When you ingest content (whether it is an AI chat conversation, a PDF, a knowledge base article, or a plain text document) Synap’s extraction pipeline breaks it down into discrete, typed memory units. It does not store raw text. Each memory has:- A type: one of five structured categories (fact, preference, episode, emotion, temporal event)
- A confidence or strength score: a 0.0 to 1.0 value indicating extraction certainty
- Source references: links back to the original document and extraction context
- Entity links: connections to resolved entities (people, organizations, concepts)
- Scope: the visibility boundary (user, customer, client, or world)
- Timestamps: creation time, last accessed time, and optional temporal anchors
A single ingested document can produce dozens or hundreds of individual memories. A five-minute conversation might yield facts about the user’s preferences, an episode describing what they discussed, temporal events about upcoming deadlines, and emotional context about how they felt.
What is Context?
Context is the assembled output that Synap delivers to your AI agent when it requests information. A context response contains:- Retrieved memories: the most relevant memories from long-term storage, ranked by relevance, recency, and confidence
- Conversation history: the accumulated short-term context from the current session (if applicable)
- Scope metadata: information about which scope levels contributed to the response
Short-term vs Long-term Memory
Synap distinguishes between two categories of memory based on their lifespan and purpose.Short-term Context
The accumulated context from the current conversation session. It builds turn by turn as the user and agent exchange messages. Short-term context lives only for the duration of the conversation and is managed through context compaction to stay within token limits.Characteristics:
- Ephemeral: exists only during the active session
- Grows with each conversational turn
- Subject to compaction when it exceeds configured thresholds
- Contains the immediate conversational state, recent decisions, and in-progress topics
Long-term Context
Extracted, structured knowledge that persists across conversations and sessions. Long-term memories are produced by the ingestion pipeline and stored in vector and graph engines. They survive indefinitely (subject to retention policies) and are retrieved based on relevance to the current query.Characteristics:
- Persistent: survives across sessions, days, months
- Built from ingested documents via the extraction pipeline
- Stored in vector and graph storage engines
- Retrieved based on semantic relevance, recency, and confidence scoring
Memory types
Synap’s extraction pipeline produces five distinct types of structured memory. Each type captures a different dimension of knowledge and maps to a field on the context response.
Facts provide grounding, preferences enable personalization, episodes give narrative continuity, emotions support empathy, and temporal events enable time-awareness.
Terminology. “Confidence”, “extraction confidence”, and “extraction certainty” all refer to the same number on a Fact. Preferences use a parallel concept called
strength, Episodes use significance, and Emotions use intensity. Use the field name that matches the memory type you’re inspecting.Facts
Facts are the backbone of long-term memory. A fact is a verifiable, declarative statement extracted from ingested content: knowledge about people, organizations, products, processes, and the world. Each fact carries aconfidence score between 0.0 and 1.0 reflecting how certain the pipeline is that the extracted fact is accurate.
- 0.9-1.0: Explicitly stated, unambiguous facts (“The company was founded in 2019”)
- 0.7-0.9: Strongly implied or clearly inferable facts (“The team uses agile methodology”)
- 0.5-0.7: Moderately confident extractions, may need verification
- Below 0.5: Low confidence, typically filtered out at ingest
confidence value plays two roles: at ingest it acts as a hard filter (default threshold 0.7), and at retrieval it is returned on every fact (fact.confidence) so your agent can decide whether to trust, qualify, or ignore each one. Higher-confidence facts surface before lower-confidence ones at the same relevance level, and conflicting facts across scopes are resolved by scope priority (user > customer > client > world).
Preferences
Preferences capture likes, dislikes, behavioral tendencies, and personal choices: what enables your agent to personalize its responses. Each has a direction (positive = likes/wants, negative = dislikes/avoids) and a strength (0.0 = mild, 1.0 = very strong).
A positive preference for “concise responses” at strength 0.9 tells the agent to keep answers short; a negative preference for “jargon” at strength 0.7 tells it to use plain language.
Episodes
Episodes capture event narratives: things that happened, interactions that occurred, activities that took place. They give your agent a sense of history and narrative continuity, answering the question “What happened?” Each carries asignificance score (0.0-1.0) indicating how important or impactful the episode is, from major decisions and milestones (0.8+) down to routine mentions.
Episodes let the agent reference past decisions (“In our previous meeting, you decided to use PostgreSQL”) and demonstrate continuity in ongoing relationships.
Emotions
Emotions capture detected emotional states, sentiment, and affective signals from conversations, enabling your agent to respond with empathy, recognizing when a user is frustrated, excited, anxious, or satisfied. Each carries anintensity score (0.0-1.0) reflecting how strongly the emotion was expressed.
Emotional memories let the agent acknowledge feelings, adjust tone, celebrate wins, and approach sensitive topics carefully.
Emotion extraction is optional. Synap turns it off automatically for use cases where it does not apply (e.g., technical Q&A bots) based on your use-case file.
Temporal events
Temporal events capture time-anchored information (dates, deadlines, recurring schedules, and time-sensitive facts) making your agent time-aware. Each has anevent_type:
Point-in-time
Point-in-time
A specific, one-time event anchored to a particular date or time, e.g. “Board meeting on March 15, 2026” or “API v3 launched on January 20, 2026”.
Recurring
Recurring
An event that repeats on a schedule, e.g. “Sprint reviews every other Friday at 2pm” or “Monthly all-hands on the first Monday of each month”.
Deadline
Deadline
A time-bound constraint or due date, e.g. “Q2 OKRs due by June 30” or “Contract renewal deadline: April 15”.
Which types your Instance extracts
Synap decides which of the five types to extract based on your agent’s Use-Case Markdown file. Mention the behavior you need (personalization, continuity, emotional awareness, scheduling) and Synap enables the right categories. Types your agent will never use are skipped to save processing time and storage.
If your agent’s use case changes, re-upload the use-case file and Synap will update the active configuration. See Customized Memory Architectures.
Filtering by type during retrieval
When fetching context, use thetypes parameter to return only specific memory types:
How memories become context
The journey from raw data to delivered context follows a well-defined pipeline.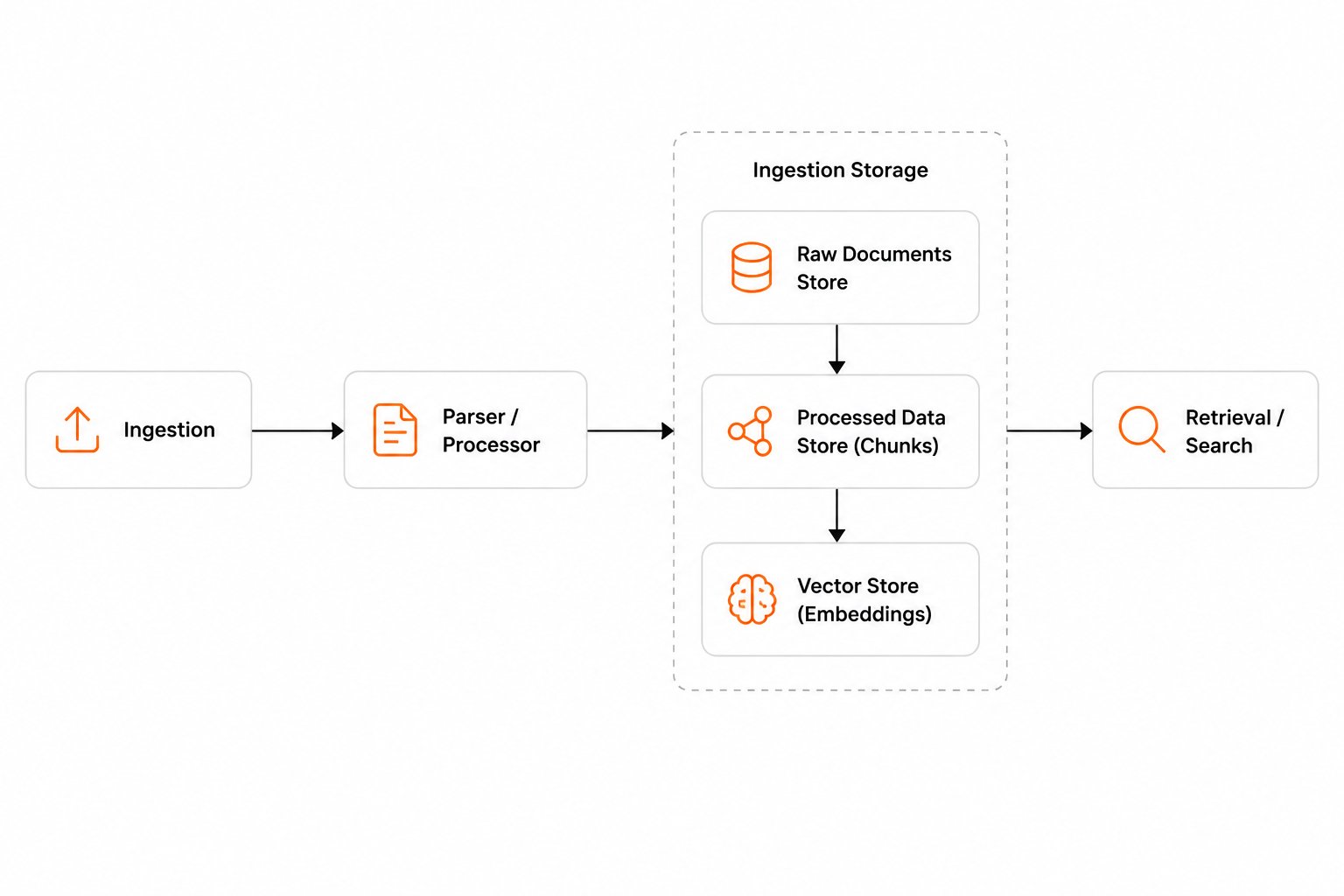
1
Ingestion
You submit raw content to Synap via the SDK. This can be an AI chat conversation, a document, a knowledge base article, or any text content. You specify the
document_type, and optionally the user_id and customer_id to set the scope.2
Extraction
Synap’s pipeline processes the raw content through multiple extraction stages. It identifies entities, resolves them against known entities, and extracts structured memories (facts, preferences, episodes, emotions, temporal events) with confidence scores and source references.
3
Storage
Extracted memories are stored in both vector storage (for semantic similarity search) and graph storage (for entity relationships and structured queries). Memories are indexed by scope, type, entity, and embedding vector.
4
Retrieval
When your agent needs context, it sends a retrieval request with search queries and scope identifiers. Synap searches across applicable scope levels, finding memories that are semantically relevant to the query.
5
Context Assembly
Retrieved memories are merged across scopes, deduplicated, ranked by relevance/recency/confidence, and assembled into a structured context response. This response is delivered to your agent, ready to inform its next output.
Next steps
Context End-to-End
How short-term and long-term context accumulate, compact, and combine across a session.
Retrieval Modes
Fast (vector + graph) versus accurate (adds LLM subquery decomposition + reranking).
Memory Scopes
How memory isolation works across users, customers, and organizations.
How Ingestion Works
The extraction pipeline that turns raw documents into typed memories.